「LLMに『次は上がる?』と聞いて、その答えに従ってボタンを押す」
そんな単純な仕組みを想像しているなら、悪いが期待外れだ。
現在の生成AI(LLM)の推論能力は強力だが、金融市場のようにノイズが多く、かつ決定的なルール(損切りラインや資金管理)が求められる領域において、プロンプト一つで勝てるほど甘い世界ではない。LLMの出力には常に「非決定論的な揺らぎ」がつきまとう。
本連載では、単一のAIモデルに依存するのではなく、「確率的な推論を行うAIエージェント」と「決定論的なルールベース・エンジン」を組み合わせたハイブリッド型自動トレーディングシステムの構築プロセスを、泥臭い実装ログとして記録していく。
何を作るのか:AIハイブリッド型自動トレード・アーキテクチャ
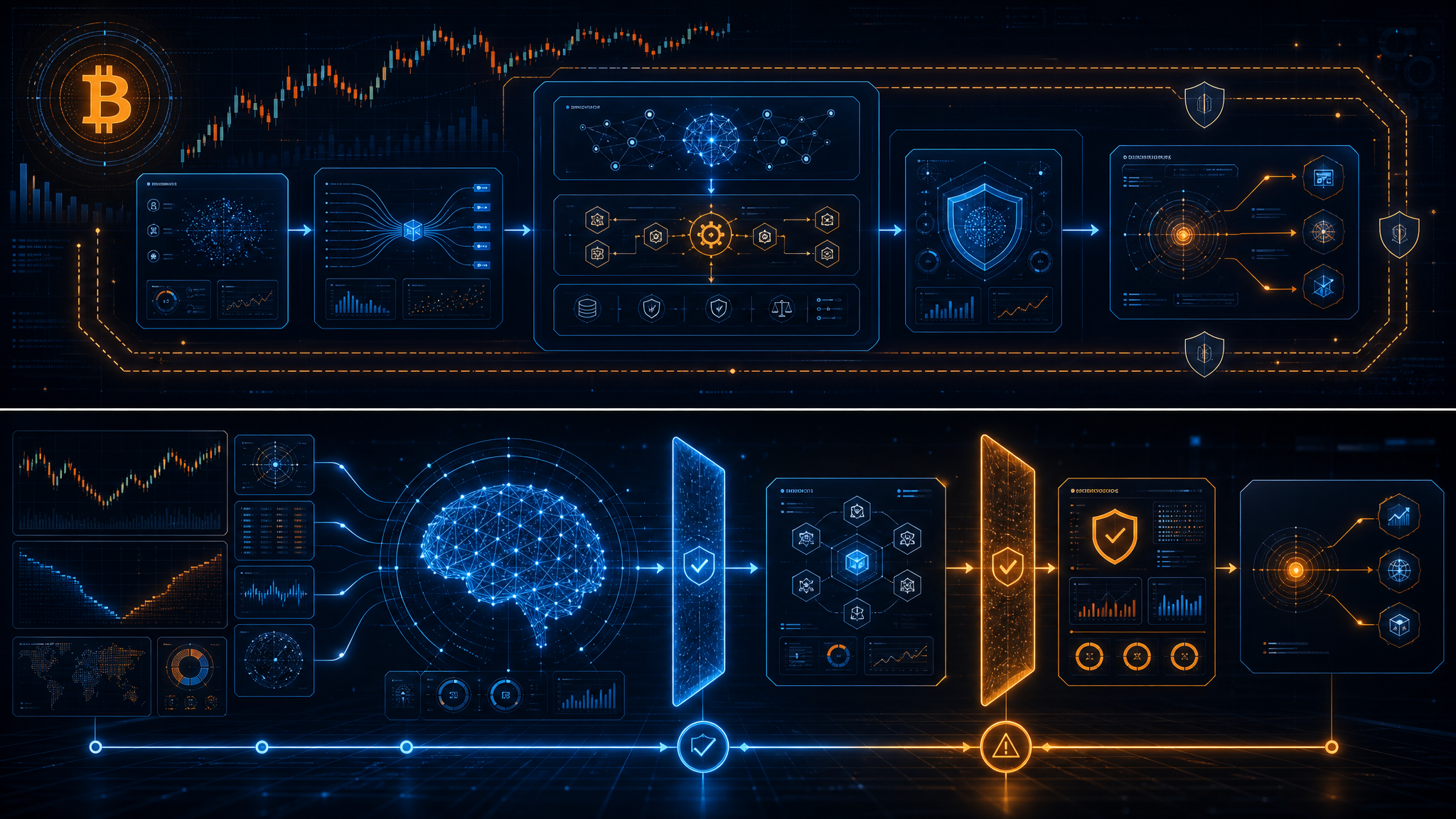
目指すのは、以下の4つのレイヤーが独立して動作し、相互にフィードバックを行う自律的なエージェント・システムだ。
1. Data Ingestion Layer (データ収集)
取引所のAPI、オンチェーンデータ、SNS(X等)のスクレイピング結果を、構造化された状態でストックする。
2. AI Agent Layer (推論・解釈)
ローカルLLM(Llama 3系などを想定)を活用し、テクニカル指標のパターン認識や、ニュースのセンチメント分析を行う。「なぜ今、この動きが起きているのか」という文脈を言語化させ、スコアリングする。
3. Decision Engine Layer (ルールベース・ロジック)
AIが出したスコアに対し、厳格な数学的ルール(RSI、ボリンジャーバンド、移動平均乖離率など)と、あらかじめ定義した資金管理ロジックを適用する。ここで「AIが強気でも、リスク許容度を超えていればエントリーしない」というガードレールを敷く。
4. Execution & Risk Management Layer (実行・監視)
最初は実資金を使わず、ペーパートレードで注文判断・ストップロス(損切り)・テイクプロフィット(利確)の動作を検証する。検証ログが十分に溜まるまでは、実注文に接続しない。
構成・実装のポイント
このシステムの肝は、「AIに判断をさせすぎない」ことにある。
- マルチエージェント化:
単一の巨大なプロンプトを作るのではなく、「テクニカル分析担当」「ニュース解析担当」「リスク評価担当」のように役割を分担させる。これにより、コンテキストウィンドウの節約と、推論精度の向上を図る。
- ローカルLLMの活用:
APIコストの爆発を防ぎ、かつ戦略の秘匿性を保つため、可能な限りローカル環境(または自前サーバー)で動作するモデルをベースにする。
- 構造化出力の強制:
LLMの回答が「なんとなく」にならないよう、JSON形式での出力を徹底させる。Pydanticなどのライブラリを用い、プログラムがそのままロジックに組み込めるスキーマを定義する。
予想されるハマりどころ
構築にあたって、すでにいくつか壁が見えている。
- 非決定論的な出力への対処:
LLMの回答が、同じ入力でも微妙に変わってしまう問題。これをどうやって「ルールベース・エンジン」が受け入れられる形式で固定化するか。
- レートリミットと遅延(Latency):
API取得、さらにはローカルLLMの推論プロセスが重なると、意思決定に致命的な遅延が発生する。リアルタイム性と計算コストのトレードオフは避けて通れない。SNSやニュースを扱う場合も、規約・取得頻度・キャッシュ設計を守る必要がある。
- コンテキストの断片化:
過去のチャートデータと最新のニュースをどうやって一つの「文脈」としてLLMに流し込むか。情報の抽象化レベルの設計が難しい。
次にやること
まずは、最も基礎となる「Data Ingestion Layer」のプロトタイプ構築から着手する。
具体的には、特定の取引所APIからOHLCV(始値・高値・安値・終値・出来高)を取得し、それをローカルのデータベースへ時系列で格納するパイプラインを実装する。
その後、そのデータに対して、どの程度の粒度のテクニカル指標を生成し、LLMにどのようなプロンプトで食わせるのが最も「解釈」として有用かを検証していく予定だ。
注意点
本プロジェクトは、あくまでシステム構築の技術的な実験であり、自動化されたエージェントがどのように動くかを観察するためのものである。市場のボラティリティや予期せぬバグにより、資産を失うリスクは常に存在する。実装コードをそのまま運用に投入することは推奨しない。
※この記事は投資助言ではなく、システム構築・検証ログです。

